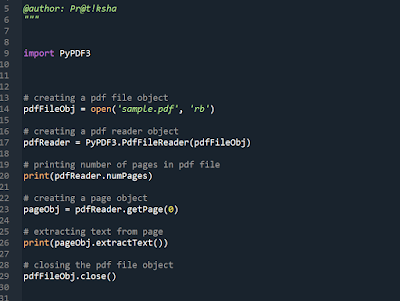
Spelling correction using TextBlob in python.
What is TextBlob?
TextBlob is python library for processing textual data. It is built on the top of NLTK module.
How to install TextBlob?
1. Using pip:
pip install textblob
2. Using conda:
conda install -c conda-forge textblob
Some terms that will be frequently used are :
· Corpus – Body of text, singular.
· Lexicon – Words and their meanings.
· Token – Each “entity” that is a part of whatever was split up based on rules. For examples, each word is a token when a sentence is “tokenized” into words. Each sentence can also be a token, if you tokenized the sentences out of a paragraph.
Textblob(text,tokenizer= None,
np_extractor=None,pos_tagger=None,analyzer=None,classifier=None): A general text block, meant for larger bodies of text.
Parameters:
text: string
tokenzier: (optional) A tokenizer instance. If None, defaults to WordTokenizer().
np_extractor: (optional) An NPExtractor instance. If None, defaults to FastNPExtractor().
pos_tagger: (optional) A Tagger instance. If None, defaults to NLTKTagger.
analyzer: (optional) A sentiment analyzer. If None, defaults to PatternAnalyzer.
classifier: (optional) A classifier.
classify(): Classify the blob using the blob’s classifier.
correct(): Attempt to correct the spelling of a blob.
detect_language(): Detect the blob’s language using the Google Translate API.
find(): Behaves like the built-in str.find() method. Returns an integer, the index of the first occurrence of the substring argument sub in the sub-string given by [start:end].
join(): Behaves like the built-in str.join(iterable) method, except returns a blob object.
json: The json representation of this blob.
lower(): Like str.lower(), returns new object with all lower-cased characters.
translate(from_lang=u'auto', to=u'en'): Translate the blob to another language. Uses the Google Translate API. Returns a new TextBlob.
upper(): Like str.upper(), returns new object with all upper-cased characters.
Tagging: Part-of-speech tags can be accessed through the tag property.
from textblob import TextBlob
wiki = TextBlob("Python is a high-level, general-purpose programming languages.")
print(wiki.tags)
Output: [('Python', 'NNP'), ('is', 'VBZ'), ('a', 'DT'), ('high-level', 'JJ'), ('general-purpose', 'JJ'), ('programming', 'NN'), ('languages', 'NNS')]
Noun Phrase Extraction: Noun phrases are accessed through the noun_phrases property.
print(wiki.noun_phrases)
Tokenization: You can break TextBlobs into words or sentences.
wiki = TextBlob("Python is a high-level, general-purpose programming languages."
"Explicit is better than implicit. ")
print(wiki.words)
print(wiki.sentences)
How to get correct sentence without any spelling mistake in python?
from textblob import TextBlob
gfg = TextBlob("every pian gives a lessson and every lessson chages a pirson.")
# using TextBlob.correct() method
gfg = gfg.correct()
print(gfg)
How to convert each to lower case?
gfg = TextBlob("Every Pian Gives a lessson and every Lessson chages a pirson.")
print(gfg.lower())


Comments
Post a Comment
If you have any doubt, please let me know. To check my other blog kindly check the following links:
https://pythoholic.blogspot.com/
If you are interested in reading Marathi stories and other stuff, kindly check the following link.
https://pratilipi.page.link/q8dZ4ffZwKPHUx6R9
ꜰᴏʀ ᴇxᴘʟᴏʀɪɴɢ ᴛʜᴇ ᴡᴏʀʟᴅ ᴘʟᴇᴀꜱᴇ ʜᴀᴠᴇ ʟᴏᴏᴋ ᴀɴᴅ ꜰᴏʟʟᴏᴡ.
https://maps.app.goo.gl/jnKyzdDpKMFutUqR7