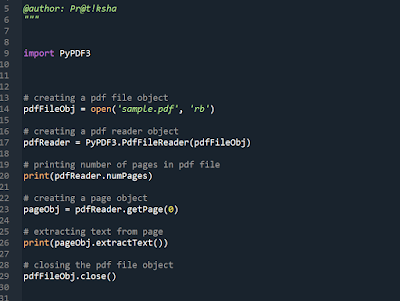
An important concept regarding machine learning.
Distribution: Distribution shows us how the probabilities of measurements are distributed.
1. Normal Distribution:- Normal distribution is always centered on the average value.

Standard Deviation: The width of the curve defines the 'standard deviation'. It is called a central limit theorem. Width of the mean value.
Mean (x̅ ): Center value or average value of the distribution.
Both represent the population called as Population Parameter. The parameters that determine how a distribution fits the population data are called Population Parameters.
2. Exponential Distribution:- It is also used for probabilities and statistics.

3. Gamma Distribution:- It is also used for probabilities and statistics. In this type of distribution, shape and rate are parameters.

Variance:


Standard Deviation:

Model: A model is a way to explore a relationship. We use statistics to determine how useful and how reliable our model is.
Hypothesis: Hypothesis means the assumption of data. Trying to find out things are the same or not. There is hypothesis testing.
- Null hypothesis testing: In this testing, there is no difference between the two things. Or no difference between the mean of groups. it is denoted as HA.

- Alternative hypothesis testing: It is opposite to the Null hypothesis. In this testing at least one group mean is different. It is denoted as Ho.




- True Positive: We predicted yes and the actual result is also yes.
- True Negative: We predicted no and the actual result is also no.
- False Positive: We predicted yes but the actual result is no
- False Negative: We predicted no but the actual result is yes.

- Horizontal Data Format:

- Vertical Data Format:



- 100% of sets with apples contain bananas.
- 50% of sets with apple, banana have watermelon.
- 50% of sets with apple, banana have any other fruits.
- Mean: Avg value. Used when data is not normally distributed. In this case, outliers occur. Outliers: It can occur by chance in distribution but they indicate either measurement error or heavy-tailed distribution.
- Median: Middle value. Used when dealing with ordinal data. Ex. Strongly dislike, dislike, like, strongly like.
- Mode: The value that occurs frequently in the dataset. Used when dealing with unordered categories data.
- Skewness: If it looks the same to the left and right of the center.
- Kurtosis: Measure of whether the data are peaked or flat relative to the rest of the data.


Comments
Post a Comment
If you have any doubt, please let me know. To check my other blog kindly check the following links:
https://pythoholic.blogspot.com/
If you are interested in reading Marathi stories and other stuff, kindly check the following link.
https://pratilipi.page.link/q8dZ4ffZwKPHUx6R9
ꜰᴏʀ ᴇxᴘʟᴏʀɪɴɢ ᴛʜᴇ ᴡᴏʀʟᴅ ᴘʟᴇᴀꜱᴇ ʜᴀᴠᴇ ʟᴏᴏᴋ ᴀɴᴅ ꜰᴏʟʟᴏᴡ.
https://maps.app.goo.gl/jnKyzdDpKMFutUqR7