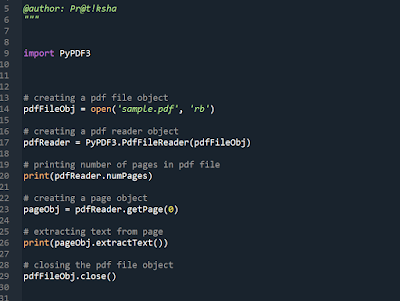
Web Scraping using BeautifulSoup library.
What is it a Beautifulsoup library? Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree.
To install Beautifulsoup: pip install bs4
What is the requests library? The library is the de facto standard
for making HTTP requests in Python. It abstracts the complexities of making
requests behind a beautiful, simple API so that you can focus on interacting
with services and consuming data in your application.
To install requests: pip install requests
What is the html5lib library? html5lib is a pure python library for parsing HTML. It is designed to conform to the WHATWG HTML specification, as is implemented by all major web browsers.
To install html5lib: pip install html5lib
Steps:
- Installing the required third-party libraries.
- Accessing the HTML content from the webpage.
- Parsing the HTML content.
- Searching and navigating through the parse tree.

- r.content: It is a raw HTML content
- html5lib: Specifying the HTML parser we want to use.
- find( ): Finding out the first tag with the specified name or id and returning an object of type bs4. E.g. find(name, attrs, recursive, string, limit, **kwargs)
- findAll( ): Finding all tags with the specified tag names or id and returning them as a list of type bs4. E.g. find_all(name, attrs, recursive, string, limit, **kwargs)
- find_parents( ): These search methods use to iterate over all the parents and check each one against the provided filter to see if it matches. E.g. find_parents(name, attrs, recursive, string, limit, **kwargs)


Other tools for Web scraping:
- Scrapy: Scrapy is a fast high-level web scraping framework, used to crawl websites and extract structured data from their pages. To install scrapy: pip install scrapy or conda install -c conda-forge scrapy
- Selenium: The selenium package is used to automate web browser interaction from python. To install selenium: pip install selenium.
Thank you very much for reading.😊 Please read other articles.

Comments
Post a Comment
If you have any doubt, please let me know. To check my other blog kindly check the following links:
https://pythoholic.blogspot.com/
If you are interested in reading Marathi stories and other stuff, kindly check the following link.
https://pratilipi.page.link/q8dZ4ffZwKPHUx6R9
ꜰᴏʀ ᴇxᴘʟᴏʀɪɴɢ ᴛʜᴇ ᴡᴏʀʟᴅ ᴘʟᴇᴀꜱᴇ ʜᴀᴠᴇ ʟᴏᴏᴋ ᴀɴᴅ ꜰᴏʟʟᴏᴡ.
https://maps.app.goo.gl/jnKyzdDpKMFutUqR7